Objetivo
Tcp Server… de novo??
Sim. Na verdade essa história começou logo que eu publiquei o post da parte 10. Meu amigo Alexandre Costa (aka Magoo) estava acompanhando o post depois que discutimos o assunto num café e logo que saiu, ele me mandou via twitter: “Por que você não usou a TPL?”.
Estragou meu dia. Toca a procurar sobre a tal da TPL e entender o que muda na prática.
A idéia aqui foi essa, fui atrás do que é a lib, uma forma de aplicá-la e ver o quanto agrega ao problema como um todo.
TPL ou Task Parallel Library
A Task Parallel Library é uma lib para trabalhar com paralelismo no .NET. A documentação da mesma encontra-se em: http://msdn.microsoft.com/en-us/library/dd460717.aspx.
No meu problema, percebi que tinha 2 situações em específico que ela poderia ajudar:
- Usar o Parallel.Invoke, para processar a resposta do servidor em paralelo.
- Usar o “pattern” para programação assíncrona proposto pela TPL (http://msdn.microsoft.com/en-us/library/dd997423(v=vs.100).aspx)
Vamos à prática.
Tcp Server 3
Nesta versão do cliente e servidor do TCP, o que muda na prática é:
public void ProcessInputQueue()
{
while (true)
{
TcpClient2InputStreamContext ctx = null;
lock (inputQueue)
{
if (inputQueue.Count > 0)
ctx = inputQueue.Dequeue();
}
if (ctx == null)
{
Thread.Sleep(250);
continue;
}
Parallel.Invoke(() =>
{
Stream inputStream = ctx.InputStream;
ctx.InputStream = null;
inputStream.Seek(0, SeekOrigin.Begin);
Log.LogMessage("Before import stream " + ctx.ID.ToString());
StreamUtil.ImportarStream(ConnString, inputStream, Log);
Log.LogMessage("Stream imported " + ctx.ID.ToString());
responsesProcessed++;
});
if (responsesProcessed == TotalBatches)
break;
}
processingDone.Set();
}
Fiz outras alterações no código, colocando um ID na pergunta e devolvendo pelo servidor, para melhorar situações de debug. Eu realmente peguei uma série de bugs nesses meus exemplos relacionados a sincronização. Ainda não está totalmente estável, mas como disse anteriormente, está longe de ser uma implementação de referência para o assunto.
Tcp Server 4
Além das melhorias feitas na versão 3, na 4 eu implementei também o pattern assíncrono proposto. Na prática, tudo que é BeginRead, EndRead e BeginWrite e EndWrite são substituídos por construções na TPL. Isso tudo foi tratado no cliente e no servidor.
Na prática, não muda nada. Existe a vantagem de poder inserir um callback para tratamento de exceções (exceções em threads não param o fluxo principal e são bem chatas de debugar) e não ter que chamar o “EndRead” no callback (ele já é chamado automaticamente pela TPL).
Fica mais ou menos assim:
private void WriteHeader(NetworkStream stream)
{
batchesSent++;
if (batchesSent > TotalBatches)
{
//Mark end of transfer.
byte[] b = new byte[sizeof(long)];
b = BitConverter.GetBytes((long)0);
stream.Write(b, 0, sizeof(long));
sendDone.Set();
return;
}
Log.LogMessage("Sending request " + batchesSent.ToString());
TcpClient2OutputStreamContext ctx = new TcpClient2OutputStreamContext();
ctx.OutputStream = new MemoryStream();
ctx.ClientStream = stream;
StreamUtil.GenerateBigRequest(ctx.OutputStream, false, recordCount, recordCount + (BatchSize - 1));
ctx.OutputStream.Seek(0, SeekOrigin.Begin);
byte[] header = BitConverter.GetBytes(ctx.OutputStream.Length);
Task.Factory.FromAsync<byte[], int, int>(stream.BeginWrite, stream.EndWrite, header, 0, header.Length, ctx).ContinueWith(BeginWriteCallback).ContinueWith(TaskExceptionHandler, TaskContinuationOptions.OnlyOnFaulted);
recordCount += BatchSize;
}
O trecho que compõe a chamada da TPL é o Task.Factory.FromAsync. Vou tentar explicar:
- No FromAsync, significa que os 3 parâmetros tratados pela função serão dos tipos especificados (que são os parâmetros da função BeginWrite)
- stream.BeginWrite é o método que será chamado, usando o pattern assíncrono
- stream.EndWrite é o método que será chamado imediatamente antes do callback. Ele é chamamdo automaticamente pela biblioteca, por isso foi removido do callback (no caso BeginWriteCallback)
- header, 0 e header.Length são os parâmetros que serão passados para BeginWrite
- ctx é o objeto de estado que será devolvido também no callback.
- Em seguida, pode-se encadear vários “ContinueWith”. O primeiro, BeginWriteCallback é de fato para tratar o processamento da Stream. O segundo será chamado somente no caso de erro, para mandar para a console o erro
Agora veremos como fica o callback:
private void BeginWriteCallback(Task task)
{
TcpClient2OutputStreamContext ctx = (TcpClient2OutputStreamContext)task.AsyncState;
if (ctx.OutputStream.Position < ctx.OutputStream.Length)
{
byte[] buffer = new byte[bufferSize];
int read = ctx.OutputStream.Read(buffer, 0, buffer.Length);
Task t = Task.Factory.FromAsync<byte[], int, int>(ctx.ClientStream.BeginWrite, ctx.ClientStream.EndWrite, buffer, 0, read, ctx);
t.ContinueWith(BeginWriteCallback).ContinueWith(TaskExceptionHandler, TaskContinuationOptions.OnlyOnFaulted);
}
else
{
WriteHeader(ctx.ClientStream);
}
}
O callback recebe como parâmetro a Task. A propriedade AsyncState é quem devolve o objeto de estado passado no chamada da função como parâmetro.
Outro exemplo interessante é a leitura. Como neste caso, existe o retorno da quantidade de bytes que foi lida na stream que é muito importante para o tratamento da leitura. Essa construção fica da seguinte forma:
private void ReadHeader(NetworkStream stream)
{
contextCount++;
TcpClient2InputStreamContext ctx = new TcpClient2InputStreamContext();
ctx.ID = contextCount;
ctx.ClientStream = stream;
ctx.Header = new byte[sizeof(long)];
ctx.HeaderRead = false;
Task<int>.Factory.FromAsync<byte[], int, int>(stream.BeginRead, stream.EndRead, ctx.Header, 0, ctx.Header.Length, ctx).ContinueWith(BeginReadCallback).ContinueWith(TaskExceptionHandler, TaskContinuationOptions.OnlyOnFaulted); ;
}
Neste caso, usa-se a construção Task. Apenas isso muda. O callback fica da seguinte maneira:
private void BeginReadCallback(Task<int> task)
{
TcpClient2InputStreamContext ctx = (TcpClient2InputStreamContext)task.AsyncState;
int bytesRead = task.Result;
Log.LogMessage("Read " + bytesRead.ToString() + " bytes");
if (!ctx.HeaderRead)
{
Log.LogMessage("Reading Header");
ctx.ResponseSize = BitConverter.ToInt64(ctx.Header, 0);
ctx.TotalRead = 0;
Log.LogMessage("Response Size: " + ctx.ResponseSize.ToString());
ctx.Header = null; //I don't need this buffer anymore.
ctx.HeaderRead = true;
ctx.InputStream = new MemoryStream();
ctx.InputStream.SetLength(ctx.ResponseSize);
if (ctx.ResponseSize > 0)
{
ctx.Buffer = new byte[bufferSize];
int bytesToRead = (ctx.ResponseSize - ctx.TotalRead) > ctx.Buffer.Length ? ctx.Buffer.Length : (int)(ctx.ResponseSize - ctx.TotalRead);
Log.LogMessage("Reading " + bytesToRead.ToString() + " bytes");
Task<int>.Factory.FromAsync<byte[], int, int>(ctx.ClientStream.BeginRead, ctx.ClientStream.EndRead, ctx.Buffer, 0, bytesToRead,
ctx).ContinueWith(BeginReadCallback).ContinueWith(TaskExceptionHandler, TaskContinuationOptions.OnlyOnFaulted); ;
}
else
receiveDone.Set();
}
else
{
ctx.TotalRead += bytesRead;
Log.LogMessage("Writing " + bytesRead.ToString() + " to input stream");
ctx.InputStream.Write(ctx.Buffer, 0, bytesRead);
if (ctx.TotalRead < ctx.ResponseSize)
{
int bytesToRead = (ctx.ResponseSize - ctx.TotalRead) > ctx.Buffer.Length ? ctx.Buffer.Length : (int)(ctx.ResponseSize - ctx.TotalRead);
Log.LogMessage("Reading " + bytesToRead.ToString() + " bytes");
ctx.Buffer = new byte[bufferSize];
Task<int>.Factory.FromAsync<byte[], int, int>(ctx.ClientStream.BeginRead, ctx.ClientStream.EndRead, ctx.Buffer, 0, bytesToRead, ctx).ContinueWith(BeginReadCallback).ContinueWith(TaskExceptionHandler, TaskContinuationOptions.OnlyOnFaulted);
}
else
{
Log.LogMessage("Finished reading " + ctx.InputStream.Length.ToString() + " bytes");
lock (inputQueue)
inputQueue.Enqueue(ctx);
ReadHeader(ctx.ClientStream);
}
}
}
Os pontos relevantes é que o tipo recebido no callback também é Task. A forma de obter o objeto de estado é a mesma e a resposta do método BeginRead, vem pelo parâmetro task.Result. O resto, mesma coisa.
Os tempos
Agora é a parte divertida. Vou comparar as 3 coisas: O modo “roots” que eu fiz anteriormente, criando todas as threads e tratamentos manualmente (Tcp Server 2), a versão 3 que somente trata o processamento de forma paralela e a versão 4 que também implementa o pattern assíncrono. Seguem os números:
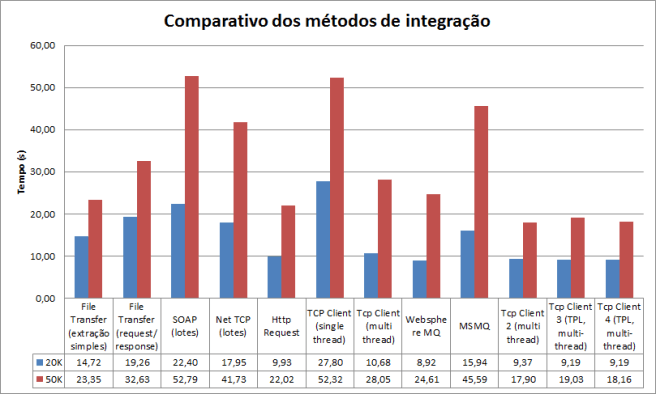
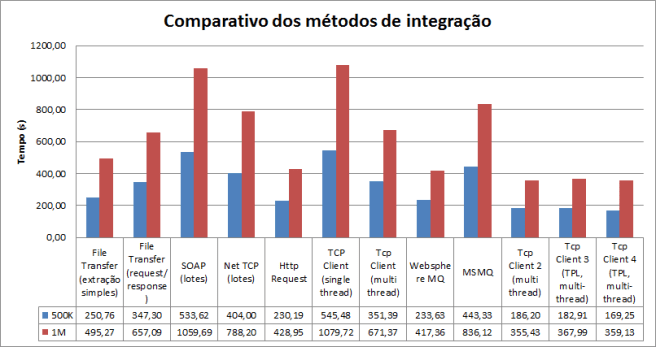
Código fonte
O código fonte está atualizado no git hub: https://github.com/ericlemes/IntegrationTests.
Ele tem uma série de coisas a melhorar, existem problemas de isolamento de responsabilidades e muita coisa a refatorar, porém, acredito que atinge o objetivo aqui proposto.
Conclusão
Como vemos nos números, as diferenças são insignificantes. Meu palpite é que a quantidade de paralelismo envolvida é muito pequena. O pesado do processamento está mesmo em tratar as streams de forma assíncrona com I/O não bloqueante (implementado no servidor 2).
Sobre a TPL, ela implementa uma sintaxe bastante elegante. Não pude estudá-la de forma exaustiva, mas a princípio não vejo nada que ela traga de novo em relação ao tratamento manual das threads.
Isso mais uma vez reforça minha idéia de aprender os conceitos na raiz. O princípio de como lidar com threads é o mesmo independente de como é a implementação. Muitas dessas bibliotecas tem por objetivo tornar a sintaxe apenas mais simples, o que pode ser as vezes uma armadilha. A simplicidade por vezes acaba escondendo o conceito que existe por tras da tecnologia fazendo com que a usemos de forma incorreta. Este exercício é bem didático neste sentido. Existe um consenso de que “sempre” paralelizar trás ganhos de performance o que na prática não se mostra verdadeiro.
