Introdução
Recentemente, comecei a fazer alguns estudos referentes à parte de programação assíncrona do .NET 4.5. Para chegar no conceito de como funciona a parte de I/O assíncrono, achei interessante voltar um pouco e começar pelas raízes da programação paralela, com o objetivo de ilustrar claramente as diferenças e como esses conceitos se combinam. Daí nasceu essa série.
Nesse post abordarei o conceito básico de threads, trocas de contexto e como isso pode resultar em desempenho pior do que aplicações que não utilizam nenhum processamento paralelo.
Afinal, o que é uma thread?
Antes de explicar uma thread, acho melhor explicar primeiro o que é um processo. Um processo nada mais é do que uma instância de um executável, na memória do computador, ou seja, cada aplicação ou serviço executam num processo. Basta ver a lista do seu task manager. Lá você tem uma lista de processos. Se você executa duas vezes a mesma aplicação, tem 2 processos executando, apesar do executável ser o mesmo.
Um processo tem suas próprias áreas de memória, seu stack e seu heap (no caso do .NET, managed heap), ou seja, um processo não invade a área de memória do outro processo. Quem vem de .NET não sabe muito bem o que isso significa na prática, mas quem vem de linguagens não gerenciadas (como C++) sabe bem do que eu estou falando. Se por alguma razão, fizer um deslocamento que dá numa região da memória utilizada por outro processo, seu processo capota (ainda bem).
Então o que é uma thread? Eu costumo explicar uma thread como “uma linha de execução separada” dentro de um mesmo processo. Neste caso, o heap é compartilhado por todas as threads do processo, e cada thread tem sua stack separada. De forma bem simplista, isso significa que se você criar uma instância de uma classe e acessá-la de duas diferentes threads, elas estarão no mesmo espaço de memória o que pode gerar efeitos indesejados em sua aplicação, porém as variáveis locais utilizadas não serão compartilhadas. O post Tipos Escalares e Tipos Complexos ou Tipos por Valor e Referência pode ajudar no entendimento destes conceitos.
O básico da idéia de threads está em:
public void DoSomething()
{
//Algum processamento.
}
public void DoSomethingInParallel()
{
Thread t = new Thread(DoSomething);
t.Start();
DoSomething();
}
No exemplo acima, ao executar “DoSomethingInParallel”, sua máquina executará duas vezes, simultaneamente, o método “DoSomething”, uma na thread principal (sempre que um novo processo inicia, ele tem uma thread principal) e outra numa thread secundária criada ao executar new Thread, passando como parâmetro um delegate do tipo ThreadStart criado a partir do método DoSomething.
Qual é o limite de threads?
Aqui as coisas começam a ficar complicadas. Não há um limite exato de threads, ou seja, pode-se criar centenas de threads num computador. Talvez a pergunta mais apropriada seja: até onde é eficiente paralelizar um processamento?
Não há uma resposta exata para essa pergunta, mas, existem algumas informações que podem nos ajudar a chegar nesse número mágico.
O limite máximo para execução em paralelo numa máquina está relacionado com o número de cores do processador da máquina, ou seja, numa máquina de 4 cores, 4 threads são executadas em paralelo. As demais, o sistema operacional acaba realizando escalonamento do processamento, ou seja, deixa uma executar um pouquinho, passa para a outra e assim sucessivamente, da mesma forma que ele faz com os processos.
O grande problema é que esse escalonamento é o que chamamos de troca de contexto, ou seja, toda vez que uma thread vai executar, o sistema operacional precisa pegar o stack daquela thread (que pode ter estar fora do cache e até mesmo em disco), recolocar na memória e reexecutar essa thread. Isso obviamente tem um custo.
A resposta para a pergunta acima é: É eficiente deixar o número de threads equivalente ao número de cores processando, sem que haja espera nessas threads. O que chamamos de espera é: espera por carregar itens da memória, operações de I/O, etc. Abordarei esse tema em mais detalhe (espera) em posts futuros.
Um pouco de prática
Para ilustrar o funcionamento das threads, criei um exemplo. A idéia é processar 400 vezes um bubble sort de uma matriz de 1000 itens. A idéia do código é criar worker threads que ficam esperando um determinado dado numa fila em memória, sempre que um dado destes é colocado, ela processa este dado, até que o trabalho todo termine. O código abaixo é o código executado por cada thread.
private void DequeueAndProcess(ConcurrentQueue<Job> queue)
{
while (true)
{
Job job = null;
if (!queue.TryDequeue(out job))
{
Thread.Sleep(0);
continue;
}
job.JobDelegate();
job.JobEndedNotifier.Set();
}
}
Cada Job acima é uma estrutura que recebe um JobDelegate (delegate que faz o trabalho quando executado) e um JobEndedNotifier (ManualResetEvent utilizado para avisar o método que cria as threads que o trabalho terminou). Usei uma queue sincronizada justamente para evitar contenção (espera) entre as threads.
Em seguida, um método que cria um número de threads, mede o tempo de execução (Stopwatch) e aguarda o término da execução de todo o trabalho.
private void CreateJobsAndProcessInParallel(int numberOfThreads)
{
ConcurrentBag<int> threadIDs = new ConcurrentBag<int>();
Stopwatch watch = new Stopwatch();
watch.Start();
ConcurrentQueue<Job> queue = new ConcurrentQueue<Job>();
List<Thread> list = new List<Thread>();
List<ManualResetEvent> eventList = new List<ManualResetEvent>();
for (int i = 0; i < numberOfThreads; i++)
{
Thread t = new Thread(() => { DequeueAndProcess(queue); });
list.Add(t);
t.Start();
}
for (int i = 0; i < numberOfJobs; i++)
{
ManualResetEvent e = new ManualResetEvent(false);
eventList.Add(e);
ThreadStart t = new ThreadStart(() =>
{
BubbleSort.DoBigBubbleSort(bubbleSize, threadIDs);
});
queue.Enqueue(new Job(t, e));
}
foreach (ManualResetEvent e in eventList)
e.WaitOne();
foreach (Thread t in list)
t.Abort();
watch.Stop();
Console.WriteLine("Total elapsed (ms): " + watch.ElapsedMilliseconds);
}
O método DoBigBubbleSort apenas executa o bubble sort e guarda uma lista de quantas diferentes threads foram usadas no processamento.
Em seguida, executei o exemplo acima com 1, 2, 4, 100, 200, 400 threads, na minha máquina que possui 4 cores (2 cores físicos, 4 processadores lógicos). Os resultados estão abaixo:
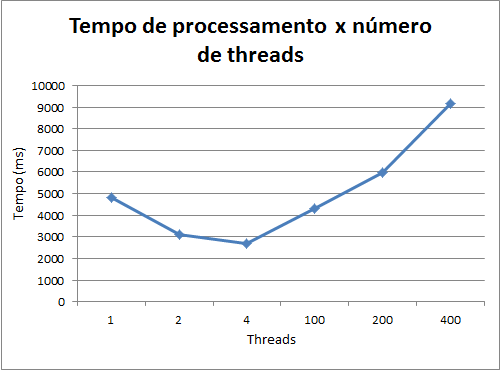
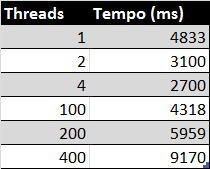
Este gráfico nos mostra algumas características muito interessantes:
- O processamento com duas threads é mais do que a metade do processamento com uma thread só. Na prática isso significa que apesar de paralelizar o processamento, a um custo para gerenciar as threads, além dos demais processos que executam no sistema operacional
- O processamento com 4 threads é um pouquinho melhor do que o processamento com 2 threads, apesar da máquina ter somente 2 cores físicos. Acredito que esse número seja explicável com a existência de 4 processadores lógicos na máquina (ver hyper threading).
- O mais interessante aqui é a partir de algo entre ~150 threads o processamento paralelo começa a ficar pior do que o processamento numa thread só. Isso é uma demonstração prática do custo de troca de contexto entre threads
Usando Task Parallel Library
Um outro exemplo, usando a TPL (Task Parallel Library):
public void TaskBasedTest()
{
ConcurrentBag<int> threadIDs = new ConcurrentBag<int>();
Stopwatch watch = new Stopwatch();
watch.Start();
List<Task> l = new List<Task>();
for (int i = 0; i < numberOfJobs; i++)
l.Add(Task.Factory.StartNew(() => { BubbleSort.DoBigBubbleSort(bubbleSize, threadIDs); }));
foreach(Task t in l)
t.Wait();
watch.Stop();
Console.WriteLine("Total elapsed (ms): " + watch.ElapsedMilliseconds);
Console.WriteLine("Number of threads used: " + threadIDs.Distinct().Count());
}
O exemplo acima, teve o seguinte tempo de execução:

Como vemos no código, não fazemos qualquer controle do número de threads. Apenas disparamos a execução e contamos quantas diferentes threads foram utilizadas no processamento. No exemplo acima, foram 5.
Como a TPL funciona? Qual é a mágica?
Sempre que executamos um Task.Factory.StartNew, estamos criando uma nova Task na TaskFactory “default”. A TaskFactory default utiliza uma implementação interna de um TaskScheduler (é uma classe abstrata). A implementação default é um ThreadPoolTaskScheduler.
Internamente, o ThreadPoolTaskScheduler delega a execução das tasks para um thread pool que procura manter sempre executando o número de threads correspondente ao número de processadores da máquina. Na prática quando recebe uma task, baseada em quantas threads estão executando, ele checa se deve ou não iniciar uma nova thread ou utilizar uma das que estão ociosas. Espertinho, não?
Na prática, quando usamos PLINQ (Parallel LINQ), Parallel.For, e outros, estamos delegando para este TaskScheduler a lógica de como quebrar o processamento em múltiplas threads, como visto no exemplo acima, um processo um tanto quanto complexo, que a API consegue nos abstrair de uma forma bem eficiente.
Código fonte do exemplo
O código ainda está uma bagunça, mesmo assim, subi para o GitHub: https://github.com/ericlemes/ParallelProgramming.

Muito bom